This is the multi-page printable view of this section. Click here to print.
How-to Guides
- 1: Configure retention policies
- 2: How to set up hierarchical metric collection
- 3: Database migrations
- 4: Job archive migrations
- 5:
- 6: Hands-On Demo
- 7: How to add a MOD notification banner
- 8: How to create a `cluster.json` file
- 9: How to customize cc-backend
- 10: How to deploy and update cc-backend
- 11: How to enable and configure auto-tagging
- 12: How to generate JWT tokens
- 13: How to plan and configure resampling
- 14: How to regenerate the Swagger UI documentation
- 15: How to setup a systemd service
- 16: How to use the REST API Endpoints
- 17: How to use the Swagger UI documentation
1 - Configure retention policies
Overview
Over time, the ClusterCockpit database and job archive can grow significantly, especially in production environments with high job counts. Retention policies help keep your storage at a manageable size by automatically removing or archiving old jobs.
Why use retention policies?
Without retention policies:
- The SQLite database file can grow to tens of gigabytes
- The job archive can reach terabytes in size
- Storage requirements increase indefinitely
- System performance may degrade
A typical multi-cluster setup over 5 years can accumulate:
- 75 GB for the SQLite database
- 1.4 TB for the job archive
Retention policies allow you to balance data retention needs with storage capacity.
Retention policy options
ClusterCockpit supports three retention policies:
None (default)
No automatic cleanup. Jobs are kept indefinitely.
{
"archive": {
"kind": "file",
"path": "./var/job-archive"
}
}
Delete
Permanently removes jobs older than the specified age from both the job archive and the database.
Use when:
- Storage space is limited
- You don’t need long-term job data
- You have external backups or data exports
Configuration example:
{
"archive": {
"kind": "file",
"path": "./var/job-archive",
"retention": {
"policy": "delete",
"age": 365,
"include-db": true
}
}
}
This configuration will:
- Delete jobs older than 365 days
- Remove them from both the job archive and database
- Run automatically based on the cleanup interval
Move
Moves old jobs to a separate location for long-term archival while removing them from the active database.
Use when:
- You need to preserve historical data
- You want to reduce active database size
- You can store archived data on cheaper, slower storage
Configuration example:
{
"archive": {
"kind": "file",
"path": "./var/job-archive",
"retention": {
"policy": "move",
"age": 365,
"location": "/mnt/archive/old-jobs",
"include-db": true
}
}
}
This configuration will:
- Move jobs older than 365 days to
/mnt/archive/old-jobs - Remove them from the active database
- Preserve the data for potential future analysis
Configuration parameters
archive.retention section
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
policy | string | Yes | - | Retention policy: none, delete, copy, or move |
age | integer | No | 7 | Age threshold in days. Jobs older than this are affected |
include-db | boolean | No | true | Also remove jobs from the database (not just archive) |
omit-tagged | string | No | none | Skip tagged jobs: none = apply to all jobs, all = skip any tagged job, user = skip jobs with user-created tags (auto-tagger tags are not user tags) |
location | string | For move/copy | - | Target directory for moved/copied jobs |
Complete configuration examples
Example 1: One-year retention with deletion
Suitable for environments with limited storage:
{
"archive": {
"kind": "file",
"path": "./var/job-archive",
"retention": {
"policy": "delete",
"age": 365,
"include-db": true
}
}
}
Example 2: Two-tier archival system
Keep 6 months active, move older data to long-term storage:
{
"archive": {
"kind": "file",
"path": "./var/job-archive",
"retention": {
"policy": "move",
"age": 180,
"location": "/mnt/slow-storage/archive",
"include-db": true
}
}
}
Example 3: S3 backend with retention
Using S3 object storage with one-year retention:
{
"archive": {
"kind": "s3",
"endpoint": "https://s3.example.com",
"bucket": "clustercockpit-jobs",
"access-key": "your-access-key",
"secret-key": "your-secret-key",
"retention": {
"policy": "delete",
"age": 365,
"include-db": true
}
}
}
How retention policies work
- Automatic execution: Retention policies run automatically based on the configured interval
- Age calculation: Jobs are evaluated based on their
startTimefield - Batch processing: All jobs older than the specified age are processed in one operation
- Database cleanup: When
include-db: true, corresponding database entries are removed - Tagged job handling: Controlled by
omit-tagged— useuserto preserve jobs tagged by users while still processing auto-tagged jobs - Archive handling: Based on policy (
deleteremoves,moverelocates)
Best practices
Planning retention periods
Consider these factors when setting the age parameter:
- Accounting requirements: Some organizations require job data for billing/auditing
- Research needs: Longer retention for research clusters where users may need historical data
- Storage capacity: Available disk space and growth rate
- Compliance: Legal or institutional data retention policies
Recommended retention periods:
| Use Case | Suggested Age |
|---|---|
| Development/testing | 30-90 days |
| Production (limited storage) | 180-365 days |
| Production (ample storage) | 365-730 days |
| Research/archival | 730+ days or use move policy |
Storage considerations
For move policy
- Mount the target
locationon slower, cheaper storage (e.g., spinning disks, network storage) - Ensure sufficient space at the target location
- Consider periodic backups of the moved archive
- Document the archive structure for future retrieval
For delete policy
- Create backups first: Always backup your database and job archive before enabling deletion
- Test on a copy: Verify the retention policy works as expected on test data
- Export important data: Consider exporting summary statistics or critical job data before deletion
Monitoring and maintenance
Track archive size: Monitor growth to adjust retention periods
du -sh /var/job-archive du -sh /path/to/database.dbVerify retention execution: Check logs for retention policy runs
grep -i retention /var/log/cc-backend.logRegular backups: Backup before changing retention settings
cp -r /var/job-archive /backup/job-archive-$(date +%Y%m%d) cp /var/clustercockpit.db /backup/clustercockpit-$(date +%Y%m%d).db
Restoring deleted jobs
If using move policy
Jobs moved to the retention location can be restored:
Stop
cc-backendUse the
archive-managertool to import jobs back:cd tools/archive-manager go build ./archive-manager -import \ -src-config '{"kind":"file","path":"/mnt/archive/old-jobs"}' \ -dst-config '{"kind":"file","path":"./var/job-archive"}'Rebuild database from archive:
./cc-backend -init-dbRestart
cc-backend
If using delete policy
Jobs cannot be restored unless you have external backups. This is why backups are critical before enabling deletion.
Related tools
- archive-manager: Manage and validate job archives
- archive-migration: Migrate archives between schema versions
- Database migration: See database migration guide
Troubleshooting
Retention policy not running
Check:
- Verify
archive.retentionis properly configured inconfig.json - Ensure
cc-backendwas restarted after configuration changes - Check logs for errors:
grep -i retention /var/log/cc-backend.log
Database size not decreasing
Possible causes:
include-db: false— Database entries are not being removedSQLite doesn’t automatically reclaim space - run
VACUUM:sqlite3 /var/clustercockpit.db "VACUUM;"
Jobs not being moved to target location
Check:
- Target directory exists and is writable
- Sufficient disk space at target location
- File permissions allow
cc-backendto write tolocation - Path in
locationis absolute, not relative
Performance impact
If retention policy execution causes performance issues:
- Consider running during off-peak hours (feature may require manual execution)
- Reduce the number of old jobs by running retention more frequently with shorter age periods
- Use more powerful hardware for the database operations
See also
2 - How to set up hierarchical metric collection
Overview
In large HPC clusters, it’s often impractical or undesirable to have every compute node connect directly to the central database. A hierarchical collection setup allows you to:
- Reduce database connections: Instead of hundreds of nodes connecting directly, use aggregation nodes as intermediaries
- Improve network efficiency: Aggregate metrics at rack or partition level before forwarding
- Add processing layers: Filter, transform, or enrich metrics at intermediate collection points
- Increase resilience: Buffer metrics during temporary database outages
This guide shows how to configure multiple cc-metric-collector instances where compute nodes send metrics to aggregation nodes, which then forward them to the backend database.
Architecture
flowchart TD
subgraph Rack1 ["Rack 1 - Compute Nodes"]
direction LR
node1["Node 1<br/>cc-metric-collector"]
node2["Node 2<br/>cc-metric-collector"]
node3["Node 3<br/>cc-metric-collector"]
end
subgraph Rack2 ["Rack 2 - Compute Nodes"]
direction LR
node4["Node 4<br/>cc-metric-collector"]
node5["Node 5<br/>cc-metric-collector"]
node6["Node 6<br/>cc-metric-collector"]
end
subgraph Aggregator ["Aggregation Node"]
ccrecv["cc-metric-collector<br/>(with receivers)"]
end
subgraph Backend ["Backend Server"]
ccms[("cc-metric-store")]
ccweb["cc-backend<br/>(Web Frontend)"]
end
node1 --> ccrecv
node2 --> ccrecv
node3 --> ccrecv
node4 --> ccrecv
node5 --> ccrecv
node6 --> ccrecv
ccrecv --> ccms
ccms <--> ccwebComponents
- Compute Node Collectors: Run on each compute node, collect local metrics, forward to aggregation node
- Aggregation Node: Receives metrics from multiple compute nodes, optionally processes them, forwards to cc-metric-store
- cc-metric-store: In-memory time-series database for metric storage and retrieval
- cc-backend: Web frontend that queries cc-metric-store and visualizes metrics
Configuration
Step 1: Configure Compute Nodes
Compute nodes collect local metrics and send them to the aggregation node using a network sink (NATS or HTTP).
Using NATS (Recommended)
NATS provides better performance, reliability, and built-in clustering support.
config.json:
{
"sinks-file": "/etc/cc-metric-collector/sinks.json",
"collectors-file": "/etc/cc-metric-collector/collectors.json",
"receivers-file": "/etc/cc-metric-collector/receivers.json",
"router-file": "/etc/cc-metric-collector/router.json",
"main": {
"interval": "10s",
"duration": "1s"
}
}
sinks.json:
{
"nats_aggregator": {
"type": "nats",
"host": "aggregator.example.org",
"port": "4222",
"subject": "metrics.rack1"
}
}
collectors.json (enable metrics you need):
{
"cpustat": {},
"memstat": {},
"diskstat": {},
"netstat": {},
"loadavg": {},
"tempstat": {}
}
router.json (add identifying tags):
{
"interval_timestamp": true,
"process_messages": {
"manipulate_messages": [
{
"add_base_tags": {
"cluster": "mycluster",
"rack": "rack1"
}
}
]
}
}
receivers.json (empty for compute nodes):
{}
Using HTTP
HTTP is simpler but less efficient for high-frequency metrics.
sinks.json (HTTP alternative):
{
"http_aggregator": {
"type": "http",
"host": "aggregator.example.org",
"port": "8080",
"path": "/api/write",
"idle_connection_timeout": "5s",
"timeout": "3s"
}
}
Step 2: Configure Aggregation Node
The aggregation node receives metrics from compute nodes via receivers and forwards them to the backend database.
config.json:
{
"sinks-file": "/etc/cc-metric-collector/sinks.json",
"collectors-file": "/etc/cc-metric-collector/collectors.json",
"receivers-file": "/etc/cc-metric-collector/receivers.json",
"router-file": "/etc/cc-metric-collector/router.json",
"main": {
"interval": "10s",
"duration": "1s"
}
}
receivers.json (receive from compute nodes):
{
"nats_rack1": {
"type": "nats",
"address": "localhost",
"port": "4222",
"subject": "metrics.rack1"
},
"nats_rack2": {
"type": "nats",
"address": "localhost",
"port": "4222",
"subject": "metrics.rack2"
}
}
sinks.json (forward to cc-metric-store):
{
"metricstore": {
"type": "http",
"host": "backend.example.org",
"port": "8082",
"path": "/api/write",
"idle_connection_timeout": "5s",
"timeout": "5s",
"jwt": "eyJ0eXAiOiJKV1QiLCJhbGciOiJFZERTQSJ9.eyJ1c2VyIjoiYWRtaW4iLCJyb2xlcyI6WyJST0xFX0FETUlOIiwiUk9MRV9VU0VSIl19.d-3_3FZTsadPjDbVXKrQr4jNiQV-B_1-uaL_lW8d8gGb-TSAG9KdMg"
}
}
Note: The jwt token must be signed with the private key corresponding to the public key configured in cc-metric-store. See JWT generation guide for details.
collectors.json (optionally collect local metrics):
{
"cpustat": {},
"memstat": {},
"loadavg": {}
}
router.json (optionally process metrics):
{
"interval_timestamp": false,
"num_cache_intervals": 0,
"process_messages": {
"manipulate_messages": [
{
"add_base_tags": {
"datacenter": "dc1"
}
}
]
}
}
Step 3: Set Up cc-metric-store
The backend server needs cc-metric-store to receive and store metrics from the aggregation node.
config.json (/etc/cc-metric-store/config.json):
{
"metrics": {
"cpu_user": {
"frequency": 10,
"aggregation": "avg"
},
"cpu_system": {
"frequency": 10,
"aggregation": "avg"
},
"mem_used": {
"frequency": 10,
"aggregation": null
},
"mem_total": {
"frequency": 10,
"aggregation": null
},
"net_bw": {
"frequency": 10,
"aggregation": "sum"
},
"flops_any": {
"frequency": 10,
"aggregation": "sum"
},
"mem_bw": {
"frequency": 10,
"aggregation": "sum"
}
},
"http-api": {
"address": "0.0.0.0:8082"
},
"jwt-public-key": "kzfYrYy+TzpanWZHJ5qSdMj5uKUWgq74BWhQG6copP0=",
"retention-in-memory": "48h",
"checkpoints": {
"interval": "12h",
"directory": "/var/lib/cc-metric-store/checkpoints",
"restore": "48h"
},
"archive": {
"interval": "24h",
"directory": "/var/lib/cc-metric-store/archive"
}
}
Important configuration notes:
- metrics: Must list ALL metrics you want to store. Only configured metrics are accepted.
- frequency: Must match the collection interval from cc-metric-collector (in seconds)
- aggregation:
"sum"for resource metrics (bandwidth, FLOPS),"avg"for diagnostic metrics (CPU %),nullfor node-only metrics - jwt-public-key: Must correspond to the private key used to sign JWT tokens in the aggregation node sink configuration
- retention-in-memory: How long to keep metrics in memory (should cover typical job durations)
Install cc-metric-store:
# Download binary
wget https://github.com/ClusterCockpit/cc-metric-store/releases/latest/download/cc-metric-store
# Install
sudo mkdir -p /opt/monitoring/cc-metric-store
sudo mv cc-metric-store /opt/monitoring/cc-metric-store/
sudo chmod +x /opt/monitoring/cc-metric-store/cc-metric-store
# Create directories
sudo mkdir -p /var/lib/cc-metric-store/checkpoints
sudo mkdir -p /var/lib/cc-metric-store/archive
sudo mkdir -p /etc/cc-metric-store
Create systemd service (/etc/systemd/system/cc-metric-store.service):
[Unit]
Description=ClusterCockpit Metric Store
After=network.target
[Service]
Type=simple
User=cc-metricstore
Group=cc-metricstore
WorkingDirectory=/opt/monitoring/cc-metric-store
ExecStart=/opt/monitoring/cc-metric-store/cc-metric-store -config /etc/cc-metric-store/config.json
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Start cc-metric-store:
# Create user
sudo useradd -r -s /bin/false cc-metricstore
sudo chown -R cc-metricstore:cc-metricstore /var/lib/cc-metric-store
# Start service
sudo systemctl daemon-reload
sudo systemctl start cc-metric-store
sudo systemctl enable cc-metric-store
# Check status
sudo systemctl status cc-metric-store
Step 4: Set Up NATS Server
The aggregation node needs a NATS server to receive metrics from compute nodes.
Install NATS:
# Using Docker
docker run -d --name nats -p 4222:4222 nats:latest
# Using package manager (example for Ubuntu/Debian)
curl -L https://github.com/nats-io/nats-server/releases/download/v2.10.5/nats-server-v2.10.5-linux-amd64.zip -o nats-server.zip
unzip nats-server.zip
sudo mv nats-server-v2.10.5-linux-amd64/nats-server /usr/local/bin/
NATS Configuration (/etc/nats/nats-server.conf):
listen: 0.0.0.0:4222
max_payload: 10MB
max_connections: 1000
# Optional: Enable authentication
authorization {
user: collector
password: secure_password
}
# Optional: Enable clustering for HA
cluster {
name: metrics-cluster
listen: 0.0.0.0:6222
}
Start NATS:
# Systemd
sudo systemctl start nats
sudo systemctl enable nats
# Or directly
nats-server -c /etc/nats/nats-server.conf
Advanced Configurations
Multiple Aggregation Levels
For very large clusters, you can create multiple aggregation levels:
flowchart TD
subgraph Compute ["Compute Nodes"]
node1["Node 1-100"]
end
subgraph Rack ["Rack Aggregators"]
agg1["Aggregator<br/>Rack 1-10"]
end
subgraph Cluster ["Cluster Aggregator"]
agg_main["Main Aggregator"]
end
subgraph Backend ["Backend"]
ccms[("cc-metric-store")]
end
node1 --> agg1
agg1 --> agg_main
agg_main --> ccmsRack-level aggregator sinks.json:
{
"cluster_aggregator": {
"type": "nats",
"host": "main-aggregator.example.org",
"port": "4222",
"subject": "metrics.cluster"
}
}
Cluster-level aggregator receivers.json:
{
"all_racks": {
"type": "nats",
"address": "localhost",
"port": "4222",
"subject": "metrics.cluster"
}
}
Load Balancing with Multiple Aggregators
Use NATS queue groups to distribute load across multiple aggregation nodes:
Compute node sinks.json:
{
"nats_aggregator": {
"type": "nats",
"host": "nats-cluster.example.org",
"port": "4222",
"subject": "metrics.loadbalanced"
}
}
Aggregator 1 and 2 receivers.json (identical configuration):
{
"nats_with_queue": {
"type": "nats",
"address": "localhost",
"port": "4222",
"subject": "metrics.loadbalanced",
"queue_group": "aggregators"
}
}
With queue_group configured, NATS automatically distributes messages across all aggregators in the group.
Filtering at Aggregation Level
Reduce cc-metric-store load by filtering metrics at the aggregation node:
Aggregator router.json:
{
"interval_timestamp": false,
"process_messages": {
"manipulate_messages": [
{
"drop_by_name": ["cpu_idle", "cpu_guest", "cpu_guest_nice"]
},
{
"drop_by": "value == 0 && match('temp_', name)"
},
{
"add_base_tags": {
"aggregated": "true"
}
}
]
}
}
Metric Transformation
Aggregate or transform metrics before forwarding:
Aggregator router.json:
{
"interval_timestamp": false,
"num_cache_intervals": 1,
"interval_aggregates": [
{
"name": "rack_avg_temp",
"if": "name == 'temp_package_id_0'",
"function": "avg(values)",
"tags": {
"type": "rack",
"rack": "<copy>"
},
"meta": {
"unit": "degC",
"source": "aggregated"
}
}
]
}
High Availability Setup
Use multiple NATS servers in cluster mode:
NATS server 1 config:
cluster {
name: metrics-cluster
listen: 0.0.0.0:6222
routes: [
nats://nats2.example.org:6222
nats://nats3.example.org:6222
]
}
Compute node sinks.json (with failover):
{
"nats_ha": {
"type": "nats",
"host": "nats1.example.org,nats2.example.org,nats3.example.org",
"port": "4222",
"subject": "metrics.rack1"
}
}
Deployment
1. Install cc-metric-collector
On all nodes (compute and aggregation):
# Download binary
wget https://github.com/ClusterCockpit/cc-metric-collector/releases/latest/download/cc-metric-collector
# Install
sudo mkdir -p /opt/monitoring/cc-metric-collector
sudo mv cc-metric-collector /opt/monitoring/cc-metric-collector/
sudo chmod +x /opt/monitoring/cc-metric-collector/cc-metric-collector
2. Deploy Configuration Files
Compute nodes:
sudo mkdir -p /etc/cc-metric-collector
sudo cp config.json /etc/cc-metric-collector/
sudo cp sinks.json /etc/cc-metric-collector/
sudo cp collectors.json /etc/cc-metric-collector/
sudo cp receivers.json /etc/cc-metric-collector/
sudo cp router.json /etc/cc-metric-collector/
Aggregation node:
sudo mkdir -p /etc/cc-metric-collector
# Deploy aggregator-specific configs
sudo cp aggregator-config.json /etc/cc-metric-collector/config.json
sudo cp aggregator-sinks.json /etc/cc-metric-collector/sinks.json
sudo cp aggregator-receivers.json /etc/cc-metric-collector/receivers.json
# etc...
3. Create Systemd Service
On all nodes (/etc/systemd/system/cc-metric-collector.service):
[Unit]
Description=ClusterCockpit Metric Collector
After=network.target
[Service]
Type=simple
User=cc-collector
Group=cc-collector
ExecStart=/opt/monitoring/cc-metric-collector/cc-metric-collector -config /etc/cc-metric-collector/config.json
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
4. Start Services
Order of startup:
- Start cc-metric-store on backend server
- Start NATS server on aggregation node
- Start cc-metric-collector on aggregation node
- Start cc-metric-collector on compute nodes
# On backend server
sudo systemctl start cc-metric-store
# On aggregation node
sudo systemctl start nats
sudo systemctl start cc-metric-collector
# On compute nodes
sudo systemctl start cc-metric-collector
# Enable on boot (on all nodes)
sudo systemctl enable cc-metric-store # backend only
sudo systemctl enable nats # aggregator only
sudo systemctl enable cc-metric-collector
Testing and Validation
Test Compute Node → Aggregator
On compute node, run once to verify metrics are collected:
cc-metric-collector -config /etc/cc-metric-collector/config.json -once
On aggregation node, check NATS for incoming metrics:
# Subscribe to see messages
nats sub 'metrics.>'
Test Aggregator → cc-metric-store
On aggregation node, verify metrics are forwarded:
# Check logs
journalctl -u cc-metric-collector -f
On backend server, verify cc-metric-store is receiving data:
# Check cc-metric-store logs
journalctl -u cc-metric-store -f
# Query metrics via REST API (requires valid JWT token)
curl -H "Authorization: Bearer $JWT_TOKEN" \
"http://backend.example.org:8082/api/query?cluster=mycluster&from=$(date -d '5 minutes ago' +%s)&to=$(date +%s)"
Validate End-to-End
Check cc-backend to see if metrics appear for all nodes:
- Open cc-backend web interface
- Navigate to node view
- Verify metrics are displayed for compute nodes
- Check that tags (cluster, rack, etc.) are present
Monitoring and Troubleshooting
Check Collection Pipeline
# Compute node: metrics are being sent
journalctl -u cc-metric-collector -n 100 | grep -i "sent\|error"
# Aggregator: metrics are being received
journalctl -u cc-metric-collector -n 100 | grep -i "received\|error"
# NATS: check connections
nats server info
nats server list
Common Issues
Metrics not appearing in cc-metric-store:
- Check compute node → NATS connection
- Verify NATS → aggregator reception
- Check aggregator → cc-metric-store sink (verify JWT token is valid)
- Verify metrics are configured in cc-metric-store’s config.json
- Examine router filters (may be dropping metrics)
High latency:
- Reduce metric collection interval on compute nodes
- Increase batch size in aggregator sinks
- Add more aggregation nodes with load balancing
- Check network bandwidth between tiers
Memory growth on aggregator:
- Reduce
num_cache_intervalsin router - Check sink write performance
- Verify cc-metric-store is accepting writes
- Monitor NATS queue depth
Memory growth on cc-metric-store:
- Reduce
retention-in-memorysetting - Increase checkpoint frequency
- Verify archive cleanup is working
Connection failures:
- Verify firewall rules allow NATS port (4222)
- Check NATS server is running and accessible
- Test network connectivity:
telnet aggregator.example.org 4222 - Review NATS server logs:
journalctl -u nats -f
Performance Tuning
Compute nodes (reduce overhead):
{
"main": {
"interval": "30s",
"duration": "1s"
}
}
Aggregator (increase throughput):
{
"metricstore": {
"type": "http",
"host": "backend.example.org",
"port": "8082",
"path": "/api/write",
"timeout": "10s",
"idle_connection_timeout": "10s"
}
}
NATS server (handle more connections):
max_connections: 10000
max_payload: 10MB
write_deadline: "10s"
Security Considerations
NATS Authentication
NATS server config:
authorization {
users = [
{
user: "collector"
password: "$2a$11$..." # bcrypt hash
}
]
}
Compute node sinks.json:
{
"nats_aggregator": {
"type": "nats",
"host": "aggregator.example.org",
"port": "4222",
"subject": "metrics.rack1",
"username": "collector",
"password": "secure_password"
}
}
TLS Encryption
NATS server config:
tls {
cert_file: "/etc/nats/certs/server-cert.pem"
key_file: "/etc/nats/certs/server-key.pem"
ca_file: "/etc/nats/certs/ca.pem"
verify: true
}
Compute node sinks.json:
{
"nats_aggregator": {
"type": "nats",
"host": "aggregator.example.org",
"port": "4222",
"subject": "metrics.rack1",
"ssl": true,
"ssl_cert": "/etc/cc-metric-collector/certs/client-cert.pem",
"ssl_key": "/etc/cc-metric-collector/certs/client-key.pem"
}
}
Firewall Rules
On aggregation node:
# Allow NATS from compute network
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="10.0.0.0/8" port protocol="tcp" port="4222" accept'
sudo firewall-cmd --reload
On backend server:
# Allow HTTP from aggregation node to cc-metric-store
sudo firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="aggregator.example.org" port protocol="tcp" port="8082" accept'
sudo firewall-cmd --reload
Alternative: Using NATS for cc-metric-store
Instead of HTTP, you can also use NATS to send metrics from the aggregation node to cc-metric-store.
Aggregation node sinks.json:
{
"nats_metricstore": {
"type": "nats",
"host": "backend.example.org",
"port": "4222",
"subject": "metrics.store"
}
}
cc-metric-store config.json (add NATS section):
{
"metrics": { ... },
"nats": {
"address": "nats://0.0.0.0:4222",
"subscriptions": [
{
"subscribe-to": "metrics.store",
"cluster-tag": "mycluster"
}
]
},
"http-api": { ... },
"jwt-public-key": "...",
"retention-in-memory": "48h",
"checkpoints": { ... },
"archive": { ... }
}
Benefits of NATS:
- Better performance for high-frequency metrics
- Built-in message buffering
- No need for JWT tokens in sink configuration
- Easier to scale with multiple aggregators
Trade-offs:
- Requires running NATS server on backend
- More complex infrastructure
See Also
3 - Database migrations
Introduction
In general, an upgrade is nothing more than a replacement of the binary file. All the necessary files, except the database file, the configuration file and the job archive, are embedded in the binary file. It is recommended to use a directory where the file names of the binary files are named with a version indicator. This can be, for example, the date or the Unix epoch time. A symbolic link points to the version to be used. This makes it easier to switch to earlier versions.
The database and the job archive are versioned. Each release binary supports specific versions of the database and job archive. If a version mismatch is detected, the application is terminated and migration is required.
cc-backend and copying the sqlite database file
somewhere.Migrating the database
After you have backed up the database, run the following command to migrate the database to the latest version:
> ./cc-backend -migrate-db
The migration files are embedded in the binary and can also be viewed in the cc backend source tree. We use the migrate library.
If something goes wrong, you can check the status and get the current schema (here for sqlite):
> sqlite3 var/job.db
In the sqlite console execute:
.schema
to get the current database schema. You can query the current version and whether the migration failed with:
SELECT * FROM schema_migrations;
The first column indicates the current database version and the second column is a dirty flag indicating whether the migration was successful.
4 - Job archive migrations
Introduction
In general, an upgrade is nothing more than a replacement of the binary file. All the necessary files, except the database file, the configuration file and the job archive, are embedded in the binary file. It is recommended to use a directory where the file names of the binary files are named with a version indicator. This can be, for example, the date or the Unix epoch time. A symbolic link points to the version to be used. This makes it easier to switch to earlier versions.
Migrating the job archive
Notice
Don’t forget to also migrate archive jobs in case you use an archive retention policy!. Archive migration is only supported from the previous archive version.Job archive migration requires a separate tool (archive-migration), which is
part of the cc-backend source tree (build with go build ./tools/archive-migration)
and is also provided as part of the releases.
Migration is supported only between two successive releases.
You find details how to use the archive-migration tool in its reference
documentation
The cluster.json files in job-archive-new must be checked for errors, especially
whether the aggregation attribute is set correctly for all metrics.
Migration takes a few hours for large job archives (several hundred GB). A versioned job archive contains a version.txt file in the root directory of the job archive. This file contains the version as an unsigned integer.
5 -
6 - Hands-On Demo
Prerequisites
- perl
- go
- npm
- Optional: curl
- Script migrateTimestamp.pl
Documentation
You find READMEs or api docs in
- ./cc-backend/configs
- ./cc-backend/init
- ./cc-backend/api
ClusterCockpit configuration files
cc-backend
./.envPasswords and Tokens set in the environment./config.jsonConfiguration options for cc-backend
cc-metric-store
./config.jsonOptional to overwrite configuration options
cc-metric-collector
Not yet included in the hands-on setup.
Setup Components
Start by creating a base folder for all of the following steps.
mkdir clustercockpitcd clustercockpit
Setup cc-backend
- Clone Repository
git clone https://github.com/ClusterCockpit/cc-backend.gitcd cc-backend
- Build
make
- Activate & configure environment for cc-backend
cp configs/env-template.txt .env- Optional: Have a look via
vim .env - Copy the
config.jsonfile included in this tarball into the root directory of cc-backend:cp ../../config.json ./
- Back to toplevel
clustercockpitcd ..
- Prepare Datafolder and Database file
mkdir var./cc-backend -migrate-db
Setup cc-metric-store
- Clone Repository
git clone https://github.com/ClusterCockpit/cc-metric-store.gitcd cc-metric-store
- Build Go Executable
go getgo build
- Prepare Datafolders
mkdir -p var/checkpointsmkdir -p var/archive
- Update Config
vim config.json- Exchange existing setting in
metricswith the following:
"clock": { "frequency": 60, "aggregation": null },
"cpi": { "frequency": 60, "aggregation": null },
"cpu_load": { "frequency": 60, "aggregation": null },
"flops_any": { "frequency": 60, "aggregation": null },
"flops_dp": { "frequency": 60, "aggregation": null },
"flops_sp": { "frequency": 60, "aggregation": null },
"ib_bw": { "frequency": 60, "aggregation": null },
"lustre_bw": { "frequency": 60, "aggregation": null },
"mem_bw": { "frequency": 60, "aggregation": null },
"mem_used": { "frequency": 60, "aggregation": null },
"rapl_power": { "frequency": 60, "aggregation": null }
- Back to toplevel
clustercockpitcd ..
Setup Demo Data
mkdir source-datacd source-data- Download JobArchive-Source:
wget https://hpc-mover.rrze.uni-erlangen.de/HPC-Data/0x7b58aefb/eig7ahyo6fo2bais0ephuf2aitohv1ai/job-archive-dev.tar.xztar xJf job-archive-dev.tar.xzmv ./job-archive ./job-archive-sourcerm ./job-archive-dev.tar.xz
- Download CC-Metric-Store Checkpoints:
mkdir -p cc-metric-store-source/checkpointscd cc-metric-store-source/checkpointswget https://hpc-mover.rrze.uni-erlangen.de/HPC-Data/0x7b58aefb/eig7ahyo6fo2bais0ephuf2aitohv1ai/cc-metric-store-checkpoints.tar.xztar xf cc-metric-store-checkpoints.tar.xzrm cc-metric-store-checkpoints.tar.xz
- Back to
source-datacd ../..
- Run timestamp migration script. This may take tens of minutes!
cp ../migrateTimestamps.pl ../migrateTimestamps.pl- Expected output:
Starting to update start- and stoptimes in job-archive for emmy
Starting to update start- and stoptimes in job-archive for woody
Done for job-archive
Starting to update checkpoint filenames and data starttimes for emmy
Starting to update checkpoint filenames and data starttimes for woody
Done for checkpoints
- Copy
cluster.jsonfiles from source to migrated folderscp source-data/job-archive-source/emmy/cluster.json cc-backend/var/job-archive/emmy/cp source-data/job-archive-source/woody/cluster.json cc-backend/var/job-archive/woody/
- Initialize Job-Archive in SQLite3 job.db and add demo user
cd cc-backend./cc-backend -init-db -add-user demo:admin:demo- Expected output:
<6>[INFO] new user "demo" created (roles: ["admin"], auth-source: 0)
<6>[INFO] Building job table...
<6>[INFO] A total of 3936 jobs have been registered in 1.791 seconds.
- Back to toplevel
clustercockpitcd ..
Startup both Apps
- In cc-backend root:
$./cc-backend -server -dev- Starts Clustercockpit at
http:localhost:8080- Log:
<6>[INFO] HTTP server listening at :8080...
- Log:
- Use local internet browser to access interface
- You should see and be able to browse finished Jobs
- Metadata is read from SQLite3 database
- Metricdata is read from job-archive/JSON-Files
- Create User in settings (top-right corner)
- Name
apiuser - Username
apiuser - Role
API - Submit & Refresh Page
- Name
- Create JTW for
apiuser- In Userlist, press
Gen. JTWforapiuser - Save JWT for later use
- In Userlist, press
- Starts Clustercockpit at
- In cc-metric-store root:
$./cc-metric-store- Start the cc-metric-store on
http:localhost:8081, Log:
- Start the cc-metric-store on
2022/07/15 17:17:42 Loading checkpoints newer than 2022-07-13T17:17:42+02:00
2022/07/15 17:17:45 Checkpoints loaded (5621 files, 319 MB, that took 3.034652s)
2022/07/15 17:17:45 API http endpoint listening on '0.0.0.0:8081'
- Does not have a graphical interface
- Otpional: Test function by executing:
$ curl -H "Authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJFZERTQSJ9.eyJ1c2VyIjoiYWRtaW4iLCJyb2xlcyI6WyJST0xFX0FETUlOIiwiUk9MRV9BTkFMWVNUIiwiUk9MRV9VU0VSIl19.d-3_3FZTsadPjDEdsWrrQ7nS0edMAR4zjl-eK7rJU3HziNBfI9PDHDIpJVHTNN5E5SlLGLFXctWyKAkwhXL-Dw" -D - "http://localhost:8081/api/query" -d "{ \"cluster\": \"emmy\", \"from\": $(expr $(date +%s) - 60), \"to\": $(date +%s), \"queries\": [{
\"metric\": \"flops_any\",
\"host\": \"e1111\"
}] }"
HTTP/1.1 200 OK
Content-Type: application/json
Date: Fri, 15 Jul 2022 13:57:22 GMT
Content-Length: 119
{"results":[[JSON-DATA-ARRAY]]}
Development API web interfaces
The -dev flag enables web interfaces to document and test the apis:
- Local GQL Playgorund - A GraphQL playground. To use it you must have a authenticated session in the same browser.
- Local Swagger Docs - A Swagger UI. To use it you have to be logged out, so no user session in the same browser. Use the JWT token with role Api generate previously to authenticate via http header.
Use cc-backend API to start job
Enter the URL
http://localhost:8080/swagger/index.htmlin your browser.Enter your JWT token you generated for the API user by clicking the green Authorize button in the upper right part of the window.
Click the
/job/start_jobendpoint and click the Try it out button.Enter the following json into the request body text area and fill in a recent start timestamp by executing
date +%s.:
{
"jobId": 100000,
"arrayJobId": 0,
"user": "ccdemouser",
"subCluster": "main",
"cluster": "emmy",
"startTime": <date +%s>,
"project": "ccdemoproject",
"resources": [
{"hostname": "e0601"},
{"hostname": "e0823"},
{"hostname": "e0337"},
{"hostname": "e1111"}],
"numNodes": 4,
"numHwthreads": 80,
"walltime": 86400
}
- The response body should be the database id of the started job, for example:
{
"id": 3937
}
- Check in ClusterCockpit
- User
ccdemousershould appear in Users-Tab with one running job - It could take up to 5 Minutes until the Job is displayed with some current data (5 Min Short-Job Filter)
- Job then is marked with a green
runningtag - Metricdata displayed is read from cc-metric-store!
- User
Use cc-backend API to stop job
- Enter the URL
http://localhost:8080/swagger/index.htmlin your browser. - Enter your JWT token you generated for the API user by clicking the green Authorize button in the upper right part of the window.
- Click the
/job/stop_job/{id}endpoint and click the Try it out button. - Enter the database id at id that was returned by
start_joband copy the following into the request body. Replace the timestamp with a recent one:
{
"cluster": "emmy",
"jobState": "completed",
"stopTime": <RECENT TS>
}
On success a json document with the job meta data is returned.
Check in ClusterCockpit
- User
ccdemousershould appear in Users-Tab with one completed job - Job is no longer marked with a green
runningtag -> Completed! - Metricdata displayed is now read from job-archive!
- User
Check in job-archive
cd ./cc-backend/var/job-archive/emmy/100/000cd $STARTTIME- Inspect
meta.jsonanddata.json
Helper scripts
- In this tarball you can find the perl script
generate_subcluster.plthat helps to generate the subcluster section for your system. Usage: - Log into an exclusive cluster node.
- The LIKWID tools likwid-topology and likwid-bench must be in the PATH!
$./generate_subcluster.ploutputs the subcluster section onstdout
Please be aware that
- You have to enter the name and node list for the subCluster manually.
- GPU detection only works if LIKWID was build with Cuda avalable and you run likwid-topology also with Cuda loaded.
- Do not blindly trust the measured peakflops values.
- Because the script blindly relies on the CSV format output by likwid-topology this is a fragile undertaking!
7 - How to add a MOD notification banner
Overview
To add a notification banner you can add a file notice.txt to the ./var
directory of the cc-backend server. As long as this file is present all text
in this file is shown in an info banner on the homepage.
Add notification banner in web interface
As an alternative the admin role can also add and edit the notification banner
from the settings view.
8 - How to create a `cluster.json` file
Overview
Every cluster is configured using a dedicated cluster.json file, that is part
of the job archive. You can find the JSON schema for it
here.
This file provides information about the homogeneous hardware partitions within
the cluster including the node topology and the metric list. A real production
configuration is provided as part of
cc-examples.
cluster.json: Basics
The cluster.json file contains three top level parts: the name of the cluster,
the metric configuration, and the subcluster list.
You find the latest cluster.json schema
here.
Basic layout of cluster.json files:
{
"name": "fritz",
"metricConfig": [
{
"name": "cpu_load",
...
},
{
"name": "mem_used",
...
}
],
"subClusters": [
{
"name": "main",
...
},
{
"name": "spr",
...
}
]
}
cluster.json: Metric configuration
There is one metric list per cluster. You can find a list of recommended metrics and their naming here. Example for a metric list entry with only the required attributes:
"metricConfig": [
{
"name": "flops_sp",
"unit": {
"base": "Flops/s",
"prefix": "G"
},
"scope": "hwthread",
"timestep": 60,
"aggregation": "sum",
"peak": 5600,
"normal": 1000,
"caution": 200,
"alert": 50
}
]
Explanation of required attributes:
name: The metric name.unit: The metrics unit. Base can be:B(for bytes),F(for flops),B/s,F/s,Flops(for floating point operations),Flops/s(for FLOP rate),CPI(for cycles per instruction),IPC(for instructions per cycle),Hz,W(for Watts),°C, or empty string for no unit. Prefix can be:K,M,G,T,P, orE.scope: The native metric measurement resolution. Can benode,socket,memoryDomain,core,hwthread, oraccelerator.timestep: The measurement frequency in secondsaggregation: How the metric is aggregated with in node topology. Can be one ofsum,avg, or empty string for no aggregation (node level metrics).- Metric thresholds. If threshold applies for larger or smaller values depends
on optional attribute
lowerIsBetter(default false).peak: The maximum possible metric valuenormal: A common metric value levelcaution: Metric value requires attentionalert: Metric value requiring immediate attention
Optional attributes:
footprint: Is this a job footprint metric. Set to how the footprint is aggregated: Canavg,min, ormax. Footprint metrics are shown in the footprint UI component and job view polar plot.energy: Should the metric be used to calculate the job energy. Can bepower(metric has unit Watts) orenergy(metric has unit Joules).lowerIsBetter: Is lower better. Influences frontend UI and evaluation of metric thresholds. Default isfalse.restrict: Whether to restrict visibility of this metric to non-user roles (admin, support, manager). Default isfalse. When set totrue, regular users cannot view this metric.subClusters(Type: array of objects): Overwrites for specific subClusters. The metrics per default are valid for all subClusters. It is possible to overwrite or remove metrics for specific subClusters. If a metric is overwritten for a subClusters all attributes have to be set, partial overwrites are not supported. Example for a metric overwrite:
{
"name": "mem_used",
"unit": {
"base": "B",
"prefix": "G"
},
"scope": "node",
"aggregation": "sum",
"footprint": "max",
"timestep": 60,
"lowerIsBetter": true,
"peak": 256,
"normal": 128,
"caution": 200,
"alert": 240,
"subClusters": [
{
"name": "spr1tb",
"footprint": "max",
"peak": 1024,
"normal": 512,
"caution": 900,
"alert": 1000
},
{
"name": "spr2tb",
"footprint": "max",
"peak": 2048,
"normal": 1024,
"caution": 1800,
"alert": 2000
}
]
},
This metric characterizes the memory capacity used by a job. Aggregation for a job is the sum of all node values. As footprint the largest allocated memory capacity is used. For this configuration lower is better is set, which results in jobs with more than the metric thresholds are marked. There exist two subClusters with 1TB and 2TB memory capacity compared to the default 256GB.
Example for removing metrics for a subcluster:
{
"name": "vectorization_ratio",
"unit": {
"base": ""
},
"scope": "hwthread",
"aggregation": "avg",
"timestep": 60,
"peak": 100,
"normal": 60,
"caution": 40,
"alert": 10,
"subClusters": [
{
"name": "icelake",
"remove": true
}
]
}
cluster.json: subcluster configuration
SubClusters in ClusterCockpit are subsets of a cluster with homogeneous hardware. The subCluster part specifies the node topology, a list of nodes that are part of a subClusters, and the node capabilities that are used to draw the roofline diagrams.
Topology Structure
The topology section defines the hardware topology using nested arrays that map
relationships between hardware threads, cores, sockets, memory domains, and dies:
node: Flat list of all hardware thread IDs on the nodesocket: Hardware threads grouped by physical CPU socket (2D array)memoryDomain: Hardware threads grouped by NUMA domain (2D array)die: Optional grouping by CPU die within sockets (2D array). This is used for multi-die processors where each socket contains multiple dies. If not applicable, use an empty array[]core: Hardware threads grouped by physical core (2D array)accelerators: Optional list of attached accelerators (GPUs, FPGAs, etc.)
The resource ID for CPU cores is the OS processor ID. For GPUs we recommend using the PCI-E address as resource ID.
Here is an example:
{
"name": "icelake",
"nodes": "w22[01-35],w23[01-35],w24[01-20],w25[01-20]",
"processorType": "Intel Xeon Gold 6326",
"socketsPerNode": 2,
"coresPerSocket": 16,
"threadsPerCore": 1,
"flopRateScalar": {
"unit": {
"base": "F/s",
"prefix": "G"
},
"value": 432
},
"flopRateSimd": {
"unit": {
"base": "F/s",
"prefix": "G"
},
"value": 9216
},
"memoryBandwidth": {
"unit": {
"base": "B/s",
"prefix": "G"
},
"value": 350
},
"topology": {
"node": [
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56,
57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71
],
"socket": [
[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35
],
[
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71
]
],
"memoryDomain": [
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35],
[36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53],
[54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71]
],
"die": [],
"core": [
[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19],
[20],
[21],
[22],
[23],
[24],
[25],
[26],
[27],
[28],
[29],
[30],
[31],
[32],
[33],
[34],
[35],
[36],
[37],
[38],
[39],
[40],
[41],
[42],
[43],
[44],
[45],
[46],
[47],
[48],
[49],
[50],
[51],
[52],
[53],
[54],
[55],
[56],
[57],
[58],
[59],
[60],
[61],
[62],
[63],
[64],
[65],
[66],
[67],
[68],
[69],
[70],
[71]
]
}
}
Since it is tedious to write this by hand, we provide a
Perl script
as part of cc-backend that generates a subCluster template. This script only
works if the LIKWID tools are installed and in the PATH. You also need the
LIKWID library for cc-metric-store. You find instructions on how to install
LIKWID here.
Example: SubCluster with GPU Accelerators
Here is an example for a subCluster with GPU accelerators:
{
"name": "a100m80",
"nodes": "a[0531-0537],a[0631-0633],a0731,a[0831-0833],a[0931-0934]",
"processorType": "AMD Milan",
"socketsPerNode": 2,
"coresPerSocket": 64,
"threadsPerCore": 1,
"flopRateScalar": {
"unit": {
"base": "F/s",
"prefix": "G"
},
"value": 432
},
"flopRateSimd": {
"unit": {
"base": "F/s",
"prefix": "G"
},
"value": 9216
},
"memoryBandwidth": {
"unit": {
"base": "B/s",
"prefix": "G"
},
"value": 400
},
"topology": {
"node": [
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56,
57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74,
75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92,
93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108,
109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123,
124, 125, 126, 127
],
"socket": [
[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37,
38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55,
56, 57, 58, 59, 60, 61, 62, 63
],
[
64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81,
82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99,
100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113,
114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127
]
],
"memoryDomain": [
[
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37,
38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55,
56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73,
74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91,
92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107,
108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121,
122, 123, 124, 125, 126, 127
]
],
"core": [
[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7],
[8],
[9],
[10],
[11],
[12],
[13],
[14],
[15],
[16],
[17],
[18],
[19],
[20],
[21],
[22],
[23],
[24],
[25],
[26],
[27],
[28],
[29],
[30],
[31],
[32],
[33],
[34],
[35],
[36],
[37],
[38],
[39],
[40],
[41],
[42],
[43],
[44],
[45],
[46],
[47],
[48],
[49],
[50],
[51],
[52],
[53],
[54],
[55],
[56],
[57],
[58],
[59],
[60],
[61],
[62],
[63],
[64],
[65],
[66],
[67],
[68],
[69],
[70],
[71],
[73],
[74],
[75],
[76],
[77],
[78],
[79],
[80],
[81],
[82],
[83],
[84],
[85],
[86],
[87],
[88],
[89],
[90],
[91],
[92],
[93],
[94],
[95],
[96],
[97],
[98],
[99],
[100],
[101],
[102],
[103],
[104],
[105],
[106],
[107],
[108],
[109],
[110],
[111],
[112],
[113],
[114],
[115],
[116],
[117],
[118],
[119],
[120],
[121],
[122],
[123],
[124],
[125],
[126],
[127]
],
"accelerators": [
{
"id": "00000000:0E:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:13:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:49:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:4F:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:90:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:96:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:CC:00.0",
"type": "Nvidia GPU",
"model": "A100"
},
{
"id": "00000000:D1:00.0",
"type": "Nvidia GPU",
"model": "A100"
}
]
}
}
Important: Each accelerator requires three fields:
id: Unique identifier (PCI-E address recommended, e.g., “00000000:0E:00.0”)type: Type of accelerator. Valid values are:"Nvidia GPU","AMD GPU","Intel GPU"model: Specific model name (e.g., “A100”, “MI100”)
You must ensure that the metric collector as well as the Slurm adapter also uses the same identifier format (PCI-E address) as the accelerator resource ID for consistency.
9 - How to customize cc-backend
Overview
Customizing cc-backend means changing the logo, legal texts, and the login
template instead of the placeholders. You can also place a text file in ./var
to add dynamic status or notification messages to the ClusterCockpit homepage.
Replace legal texts
To replace the imprint.tmpl and privacy.tmpl legal texts, you can place your
version in ./var/. At startup cc-backend will check if ./var/imprint.tmpl and/or
./var/privacy.tmpl exist and use them instead of the built-in placeholders.
You can use the placeholders in web/templates as a blueprint.
Replace login template
To replace the default login layout and styling, you can place your version in
./var/. At startup cc-backend will check if ./var/login.tmpl exist and use
it instead of the built-in placeholder. You can use the default template
web/templates/login.tmpl as a blueprint.
Replace logo
To change the logo displayed in the navigation bar, you can provide the file
logo.png in the folder ./var/img/. On startup cc-backend will check if the
folder exists and use the images provided there instead of the built-in images.
You may also place additional images there you use in a custom login template.
Add notification banner on homepage
To add a notification banner you can add a file notice.txt to ./var. As long
as this file is present all text in this file is shown in an info banner on the
homepage.
10 - How to deploy and update cc-backend
Workflow for deployment
Why we do not provide a docker container
The ClusterCockpit web backend binary has no external dependencies, everything is included in the binary. The external assets, SQL database and job archive, would also be external in a docker setup. The only advantage of a docker setup would be that the initial configuration is automated. But this only needs to be done one time. We therefore think that setting up docker, securing and maintaining it is not worth the effort.It is recommended to install all ClusterCockpit components in a common directory, e.g. /opt/monitoring, var/monitoring or var/clustercockpit.
In the following we use /opt/monitoring.
Two systemd services run on the central monitoring server:
- clustercockpit : binary cc-backend in
/opt/monitoring/cc-backend. - cc-metric-store : Binary cc-metric-store in
/opt/monitoring/cc-metric-store.
ClusterCockpit is deployed as a single binary that embeds all static assets.
We recommend keeping all cc-backend binary versions in a folder archive and
linking the currently active one from the cc-backend root.
This allows for easy roll-back in case something doesn’t work.
Please Note
cc-backend is started with root rights to open the privileged ports (80 and
443). It is recommended to set the configuration options user and group, in
which case cc-backend will drop root permissions once the ports are taken.
You have to take care, that the ownership of the ./var folder and
its contents are set accordingly.Workflow to update
This example assumes the DB and job archive versions did not change. In case the new binary requires a newer database or job archive version read here how to migrate to newer versions.
- Stop systemd service:
sudo systemctl stop clustercockpit.service
- Backup the sqlite DB file! This is as simple as to copy it.
- Copy new
cc-backendbinary to/opt/monitoring/cc-backend/archive(Tip: Use a date tag likeYYYYMMDD-cc-backend). Here is an example:
cp ~/cc-backend /opt/monitoring/cc-backend/archive/20231124-cc-backend
- Link from
cc-backendroot to current version
ln -s /opt/monitoring/cc-backend/archive/20231124-cc-backend /opt/monitoring/cc-backend/cc-backend
- Start systemd service:
sudo systemctl start clustercockpit.service
- Check if everything is ok:
sudo systemctl status clustercockpit.service
- Check log for issues:
sudo journalctl -u clustercockpit.service
- Check the ClusterCockpit web frontend and your Slurm adapters if anything is broken!
11 - How to enable and configure auto-tagging
Overview
ClusterCockpit provides automatic job tagging to classify and categorize jobs based on configurable rules. The tagging system consists of two components:
- Application Detection - Identifies which application a job is running by matching patterns in the job script
- Job Classification - Analyzes job performance metrics to identify performance issues or characteristics
Tags are automatically applied when jobs start or stop, and can also be applied retroactively to existing jobs. This feature is disabled by default and must be explicitly enabled in the configuration.
Enable auto-tagging
Step 1: Copy configuration files
The tagging system requires configuration files to define application patterns
and classification rules. Example configurations are provided in the cc-backend
repository at configs/tagger/.
From the cc-backend root directory, copy the configuration files to the var
directory:
mkdir -p var/tagger
cp -r configs/tagger/apps var/tagger/
cp -r configs/tagger/jobclasses var/tagger/
This copies:
- Application patterns (
var/tagger/apps/) - Text files containing regex patterns to match application names in job scripts (16 example applications) - Job classification rules (
var/tagger/jobclasses/) - JSON files defining rules to classify jobs based on metrics (3 example rules) - Shared parameters (
var/tagger/jobclasses/parameters.json) - Common threshold values used across multiple classification rules
Step 2: Enable in configuration
Add or set the enable-job-taggers configuration option in your config.json:
{
"enable-job-taggers": true
}
Important: Automatic tagging is disabled by default. Setting this to true
activates automatic tagging for jobs that start or stop after cc-backend is
restarted.
Step 3: Restart cc-backend
The tagging system loads configuration from ./var/tagger/ at startup:
./cc-backend -server
Step 4: Verify configuration loaded
Check the logs for messages indicating successful initialization:
[INFO] Setup file watch for ./var/tagger/apps
[INFO] Setup file watch for ./var/tagger/jobclasses
These messages confirm the tagging system is active and watching for configuration changes.
How auto-tagging works
Automatic tagging
When enable-job-taggers is set to true, tags are automatically applied at
two points in the job lifecycle:
- Job Start - Application detection runs immediately when a job starts, analyzing the job script to identify the application
- Job Stop - Job classification runs when a job completes, analyzing metrics to identify performance characteristics
Note: Only jobs that start or stop after enabling the feature are automatically tagged. Existing jobs require manual tagging (see below).
Manual tagging (retroactive)
To apply tags to existing jobs in the database, use the -apply-tags command
line option:
./cc-backend -apply-tags
This processes all jobs in the database and applies current tagging rules. This is useful when:
- You have existing jobs created before tagging was enabled
- You’ve added new tagging rules and want to apply them to historical data
- You’ve modified existing rules and want to re-evaluate all jobs
The -apply-tags option works independently of the enable-job-taggers
configuration setting.
Hot reload
The tagging system watches configuration directories for changes. You can modify or add rules without restarting cc-backend:
- Changes to
var/tagger/apps/*are detected automatically - Changes to
var/tagger/jobclasses/*are detected automatically
Simply edit the files and the new rules will be applied to subsequent jobs.
Application detection
Application detection identifies which software a job is running by matching patterns in the job script.
Configuration format
Application patterns are stored in text files under var/tagger/apps/. Each
file represents one application, and the filename (without .txt extension)
becomes the tag name.
Each file contains one or more regular expression patterns, one per line:
Example: var/tagger/apps/vasp.txt
vasp
VASP
Example: var/tagger/apps/python.txt
python
pip
anaconda
conda
How it works
- When a job starts, the system retrieves the job script from metadata
- Each line in the app configuration files is treated as a regex pattern
- Patterns are matched case-insensitively against the lowercased job script
- If a match is found, a tag of type
appwith the filename as tag name is applied - Only the first matching application is tagged
Adding new applications
To add detection for a new application:
Create a new file in
var/tagger/apps/(e.g.,tensorflow.txt)Add regex patterns, one per line:
tensorflow tf\.keras import tensorflowThe file is automatically detected and loaded (no restart required)
The tag name will be the filename without the .txt extension (e.g.,
tensorflow).
Provided application patterns
The example configuration includes patterns for 16 common HPC applications:
- vasp
- python
- gromacs
- lammps
- openfoam
- starccm
- matlab
- julia
- cp2k
- cpmd
- chroma
- flame
- caracal
- turbomole
- orca
- alf
Job classification
Job classification analyzes completed jobs based on their metrics and properties to identify performance issues or characteristics.
Configuration format
Job classification rules are defined in JSON files under
var/tagger/jobclasses/. Each rule file contains:
- Metrics required - Which job metrics to analyze
- Requirements - Pre-conditions that must be met
- Variables - Computed values used in the rule
- Rule expression - Boolean expression that determines if the rule matches
- Hint template - Message displayed when the rule matches
Shared parameters
The file var/tagger/jobclasses/parameters.json defines threshold values used
across multiple rules:
{
"lowcpuload_threshold_factor": 0.9,
"excessivecpuload_threshold_factor": 1.1,
"job_min_duration_seconds": 600.0,
"sampling_interval_seconds": 30.0
}
These parameters can be referenced in rule expressions and make it easy to maintain consistent thresholds across multiple rules.
Rule file structure
Each classification rule is a JSON file with the following structure:
Example: var/tagger/jobclasses/lowload.json
{
"name": "Low CPU load",
"tag": "lowload",
"parameters": ["lowcpuload_threshold_factor", "job_min_duration_seconds"],
"metrics": ["cpu_load"],
"requirements": [
"job.shared == \"none\"",
"job.duration > job_min_duration_seconds"
],
"variables": [
{
"name": "load_threshold",
"expr": "job.numCores * lowcpuload_threshold_factor"
}
],
"rule": "cpu_load.avg < cpu_load.limits.caution",
"hint": "Average CPU load {{.cpu_load.avg}} falls below threshold {{.cpu_load.limits.caution}}"
}
Field descriptions
| Field | Description |
|---|---|
name | Human-readable description of the rule |
tag | Tag identifier applied when the rule matches |
parameters | List of parameter names from parameters.json to include in rule environment |
metrics | List of metrics required for evaluation (must be present in job data) |
requirements | Boolean expressions that must all be true for the rule to be evaluated |
variables | Named expressions computed before evaluating the main rule |
rule | Boolean expression that determines if the job matches this classification |
hint | Go template string for generating a user-visible message |
Expression environment
Expressions in requirements, variables, and rule have access to:
Job properties:
job.shared- Shared node allocation typejob.duration- Job runtime in secondsjob.numCores- Number of CPU coresjob.numNodes- Number of nodesjob.jobState- Job completion statejob.numAcc- Number of acceleratorsjob.smt- SMT setting
Metric statistics (for each metric in metrics):
<metric>.min- Minimum value<metric>.max- Maximum value<metric>.avg- Average value<metric>.limits.peak- Peak limit from cluster config<metric>.limits.normal- Normal threshold<metric>.limits.caution- Caution threshold<metric>.limits.alert- Alert threshold
Parameters:
- All parameters listed in the
parametersfield
Variables:
- All variables defined in the
variablesarray
Expression language
Rules use the expr language for expressions. Supported operations:
- Arithmetic:
+,-,*,/,%,^ - Comparison:
==,!=,<,<=,>,>= - Logical:
&&,||,! - Functions: Standard math functions (see expr documentation)
Hint templates
Hints use Go’s text/template syntax. Variables from the evaluation environment
are accessible:
{{.cpu_load.avg}} # Access metric average
{{.job.duration}} # Access job property
{{.load_threshold}} # Access computed variable
Adding new classification rules
To add a new classification rule:
- Create a new JSON file in
var/tagger/jobclasses/(e.g.,memoryLeak.json) - Define the rule structure following the format above
- Add any new parameters to
parameters.jsonif needed - The file is automatically detected and loaded (no restart required)
Example: Detecting memory leaks
{
"name": "Memory Leak Detection",
"tag": "memory_leak",
"parameters": ["memory_leak_slope_threshold"],
"metrics": ["mem_used"],
"requirements": ["job.duration > 3600"],
"variables": [
{
"name": "mem_growth",
"expr": "(mem_used.max - mem_used.min) / job.duration"
}
],
"rule": "mem_growth > memory_leak_slope_threshold",
"hint": "Memory usage grew by {{.mem_growth}} bytes per second"
}
Don’t forget to add memory_leak_slope_threshold to parameters.json.
Provided classification rules
The example configuration includes 3 classification rules:
- lowload - Detects jobs with low CPU load (avg CPU load below caution threshold)
- excessiveload - Detects jobs with excessive CPU load (avg CPU load above peak × threshold factor)
- lowutilization - Detects jobs with low resource utilization (flop rate below alert threshold)
Troubleshooting
Tags not applied
Check tagging is enabled: Verify
enable-job-taggers: trueis set inconfig.jsonCheck configuration exists:
ls -la var/tagger/apps ls -la var/tagger/jobclassesCheck logs for errors:
./cc-backend -server -loglevel debugVerify file permissions: Ensure cc-backend can read the configuration files
For existing jobs: Use
./cc-backend -apply-tagsto retroactively tag jobs
Rules not matching
Enable debug logging: Set log level to debug to see detailed rule evaluation:
./cc-backend -server -loglevel debugCheck requirements: Ensure all requirements in the rule are satisfied
Verify metrics exist: Classification rules require job metrics to be available in the job data
Check metric names: Ensure metric names in rules match those in your cluster configuration
File watch not working
If changes to configuration files aren’t detected automatically:
- Restart cc-backend to reload all configuration
- Check filesystem supports file watching (some network filesystems may not support inotify)
- Check logs for file watch setup messages
Best practices
- Start simple: Begin with basic rules and refine based on results
- Use requirements: Filter out irrelevant jobs early with requirements to avoid unnecessary metric processing
- Test incrementally: Add one rule at a time and verify behavior before adding more
- Document rules: Use descriptive names and clear hint messages
- Share parameters: Define common thresholds in
parameters.jsonfor consistency - Version control: Keep your
var/tagger/configuration in version control to track changes - Backup before changes: Test new rules on a development instance before deploying to production
Tag types and usage
The tagging system creates two types of tags:
app- Application tags (e.g., “vasp”, “gromacs”, “python”)jobClass- Classification tags (e.g., “lowload”, “excessiveload”, “lowutilization”)
Tags can be:
- Queried and filtered in the ClusterCockpit UI
- Used in API queries to find jobs with specific characteristics
- Referenced in reports and analytics
Tags are stored in the database and appear in the job details view, making it easy to identify application usage and performance patterns across your cluster.
12 - How to generate JWT tokens
Overview
ClusterCockpit uses JSON Web Tokens (JWT) for authorization of its APIs. JWTs are the industry standard for securing APIs and is also used for example in OAuth2. For details on JWTs refer to the JWT article in the Concepts section.
JWT tokens for cc-backend login and REST API
When a user logs in via the /login page using a browser, a session cookie
(secured using the random bytes in the SESSION_KEY env variable you should
change as well in production) is used for all requests after the successful
login. The JWTs make it easier to use the APIs of ClusterCockpit using scripts
or other external programs. The token is specified n the Authorization HTTP
header using the Bearer schema
(there is an example below). Tokens can be issued to users from the
configuration view in the Web-UI or the command line (using the -jwt <username> option). In order to use the token for API endpoints such as
/api/jobs/start_job/, the user that executes it needs to have the api role.
Regular users can only perform read-only queries and only look at data connected
to jobs they started themselves.
There are two usage scenarios:
- The APIs are used during a browser session. API accesses are authorized with the active session.
- The REST API is used outside a browser session, e.g. by scripts. In this case
you have to issue a token manually. This possible from within the
configuration view or on the command line. It is recommended to issue a JWT
token in this case for a special user that only has the
apirole. By using different users for different purposes a fine grained access control and access revocation management is possible.
The token is commonly specified in the Authorization HTTP header using the
Bearer schema. ClusterCockpit uses a ECDSA private/public keypair to sign and
verify its tokens. You can use cc-backend to generate new JWT tokens.
Create a new ECDSA Public/private key pair for signing and validating tokens
We provide a small utility tool as part of cc-backend:
go build ./cmd/gen-keypair/
./gen-keypair
Add key pair in your .env file for cc-backend
An env file template can be found in ./configs.
cc-backend requires the private key to sign newly generated JWT tokens and the
public key to validate tokens used to authenticate in its REST APIs.
Generate new JWT token
Every user with the admin role can create or change a user in the configuration view of the web interface. To generate a new JWT for a user just press the GenJWT button behind the user name in the user list.
A new api user and corresponding JWT keys can also be generated from the command line.
Create new API user with admin and api role:
./cc-backend -add-user myapiuser:admin,api:<password>
Create a new JWT token for this user:
./cc-backend -jwt myapiuser
Use issued token token on client side
curl -X GET "<API ENDPOINT>" -H "accept: application/json" -H "Content-Type: application/json" -H "Authorization: Bearer <JWT TOKEN>"
This token can be used for the cc-backend REST API as well as for the
cc-metric-store. If you use the token for cc-metric-store you have to
configure it to use the corresponding public key for validation in its
config.json.
Note
Per default the JWT tokens generated by cc-backend will not expire! To set an expiration date you have to configure an expiration duration inconfig.json.
You find details here,
use keys jwts:max-age.Of course the JWT token can be generated also by other means as long it is
signed with a ED25519 private key and the corresponding public key is configured
in cc-backend or cc-metric-store. For the claims that are set and used by
ClusterCockpit refer to the JWT article.
cc-metric-store
The cc-metric-store also
uses JWTs for authentication. As it does not issue new tokens, it does not need
to know the private key. The public key of the keypair that is used to generate
the JWTs that grant access to the cc-metric-store can be specified in its
config.json. When configuring the metricDataRepository object in the
cluster.json file of the job-archive, you can put a token issued by
cc-backend itself.
Other tools to generate signed tokens
The golang-jwt project provides a small command line tool to sign and verify tokens. You can install it with:
go install github.com/golang-jwt/jwt/v5/cmd/jwt
OpenSSL can be used to generate ED25519 key-pairs:
# Generate ed25519 private key
openssl genpkey -algorithm ed25519 -out privkey.pem
# export its public key
openssl pkey -in privkey.pem -pubout -out pubkey.pem
13 - How to plan and configure resampling
Enable timeseries resampling
ClusterCockpit now supports resampling of time series data to a lower frequency. This dramatically improves load times for very large or very long jobs, and we recommend enabling it. Resampling is supported for running as well as for finished jobs.
Note: For running jobs, this currently only works with the newest version of
cc-metric-store. Resampling support for the Prometheus time series database will be added in the future.
Resampling Algorithm
To preserve visual accuracy while reducing data points, ClusterCockpit utilizes the Largest-Triangle-Three-Buckets (LTTB) algorithm.
Standard downsampling methods often fail to represent data accurately:
- Averaging: Tends to smooth out important peaks and valleys, hiding critical performance spikes.
- Decimation (Step sampling): Simply skips points, which can lead to random data loss and missed outliers.
In contrast, LTTB uses a geometric approach to select data points that form the largest triangles effectively. This technique creates a downsampled representation that retains the perceptual shape of the original line graph, ensuring that significant extrema and performance trends remain visible even at lower resolutions.
Configuration
To enable resampling, you must add the following toplevel configuration key:
"resampling": {
"minimum-points": 300,
"trigger": 30,
"resolutions": [
600,
300,
120,
60
]
}
Configuration Parameters
The enable-resampling object is optional. If configured, it enables dynamic downsampling of metric data using the following properties:
minimum-points(Integer) Specifies the minimum number of data points required to trigger resampling. This ensures short jobs are not unnecessarily downsampled.- Example: If
minimum-pointsis set to300and if the native frequency is 60 seconds, resampling will only trigger for jobs longer than 10 hours (300 points * 60 seconds = 18,000 seconds / 3600 = 5 hours).
- Example: If
resolutions(Array [Integer]) An array of target resampling resolutions in seconds.- Example:
[600, 300, 120, 60] - Note: The finest resolution in this list must match the native resolution of your metrics. If you have different native resolutions across your metric configuration, you should use the finest available resolution here. The implementation will automatically fallback to the finest available resolution if an exact match isn’t found.
- Example:
trigger(Integer) Controls the zoom behavior. It specifies the threshold of visible data points required to trigger the next zoom level. When the number of visible points in the plot window drops below this value (due to zooming in), the backend loads the next finer resolution level.
Example view of resampling in graphs
The following examples demonstrate how the configuration above (minimum-points: 300, trigger: 30) affects the visualization of a 16-hour job.
1. Initial Overview (Coarse Resolution)
Because the job duration (~16 hours) requires more than 300 points at native resolution, the system automatically loads the 600s resolution. This provides a fast “overview” load without fetching high-frequency data. You can see in the tooltip of this example that we see datapoints every 10 minutes (because of frequency of 600).
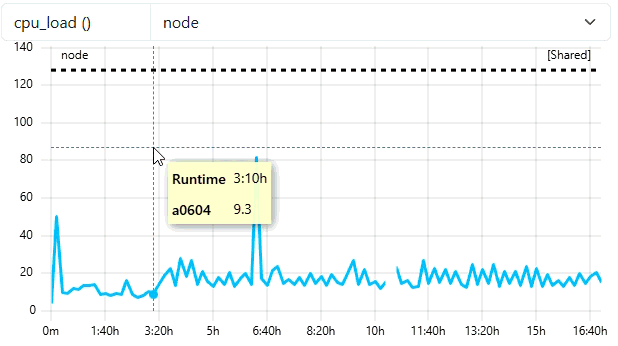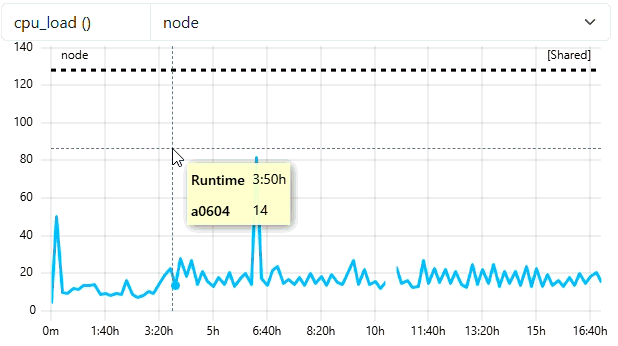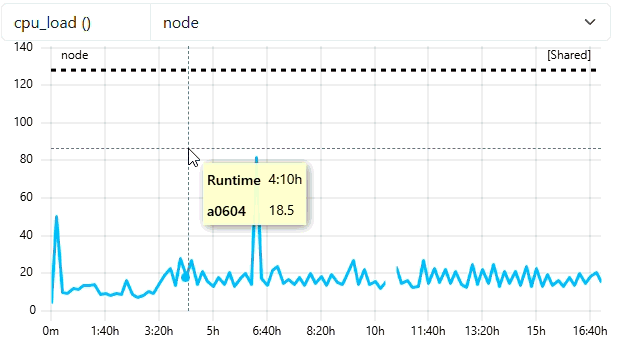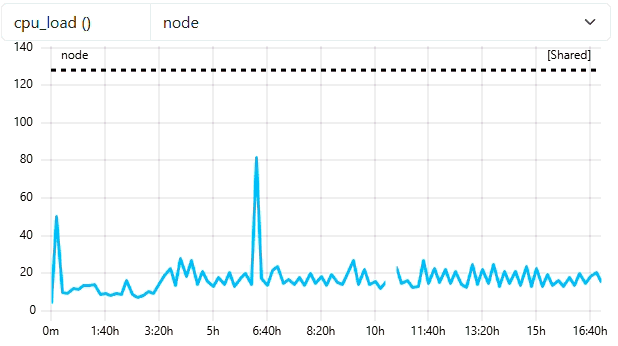
2. Zooming without Triggering
When the user zooms in, the system checks if the number of visible data points in the new view is less than the trigger value (30). In the example below, the zoomed window still contains enough points, so the resolution remains at 600s. As you can see from the tooltip of the example, we still see dataa points every 10 mins.
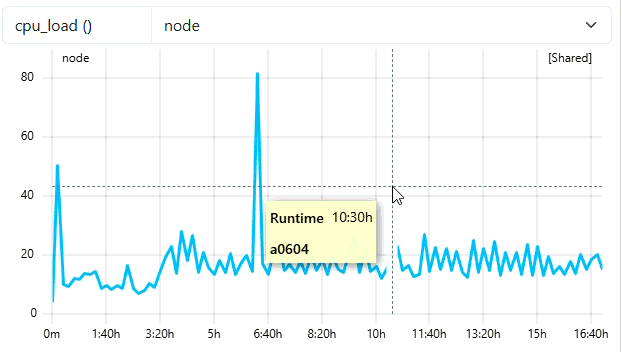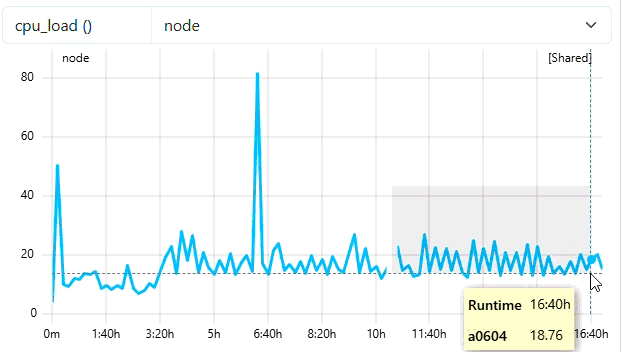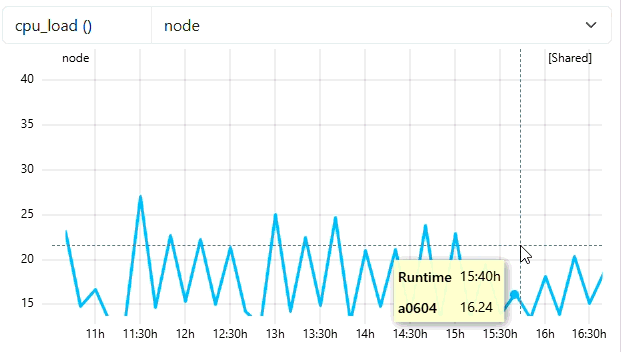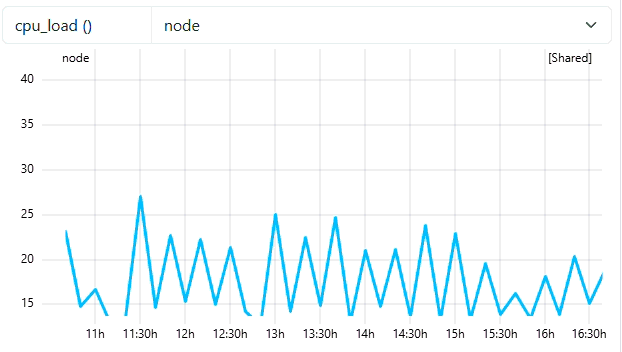
3. Zooming and Triggering Detail
As the user zooms in deeper, the number of visible points drops below the trigger threshold of 30. This signals the backend to fetch the next finer resolution (e.g., 120s or 60s). The graph updates dynamically to show the high-frequency peaks that were previously smoothed out. As you can see from the tooltip of the example, the backend has detected that the selected data points are below trigger threshold and load the second last resampling level with the frequency of 120. With native frequency of 60, a frequency of 120 means 2 mins of data. We will see data points every 2 mins as seen in the tooltip of the example.
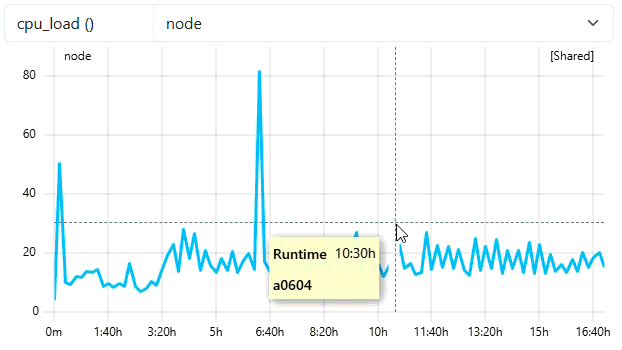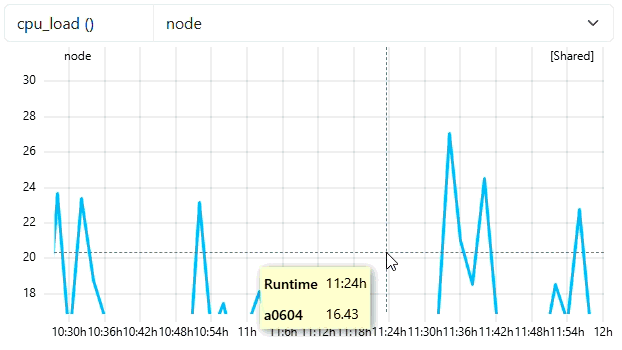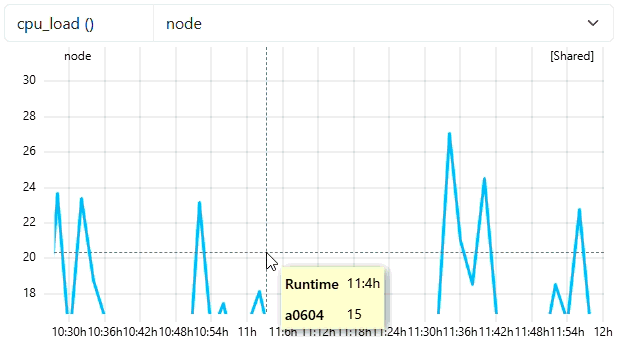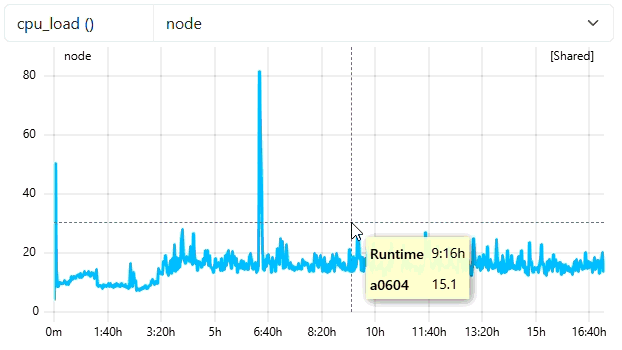
4. Visual Comparison
The animation below highlights the difference in visual density and performance between the raw data and the optimized resampled view. As you know the minimum-points is 300, means resampling will trigger only for jobs > 5 hours of duration (assuming native frequency of 60).
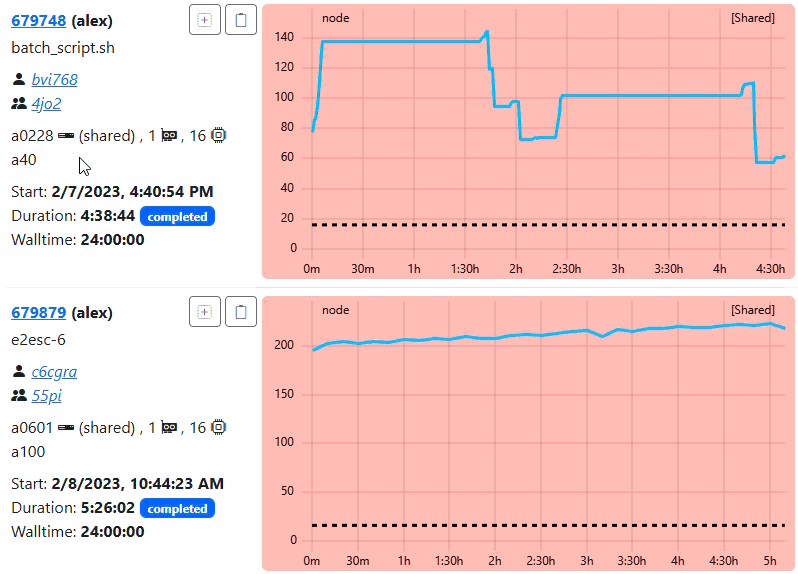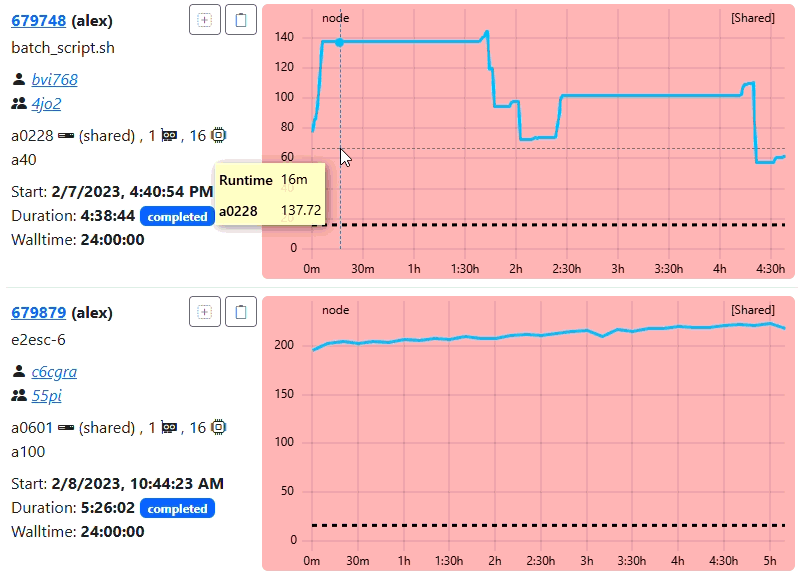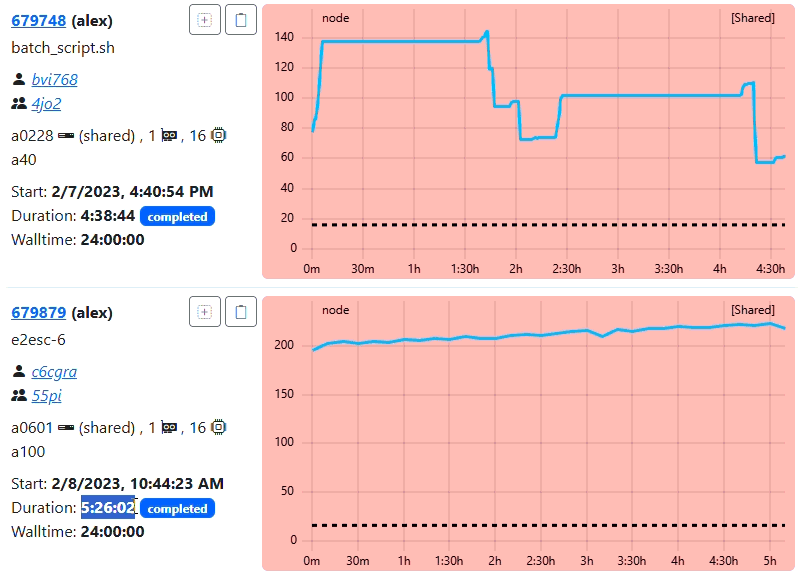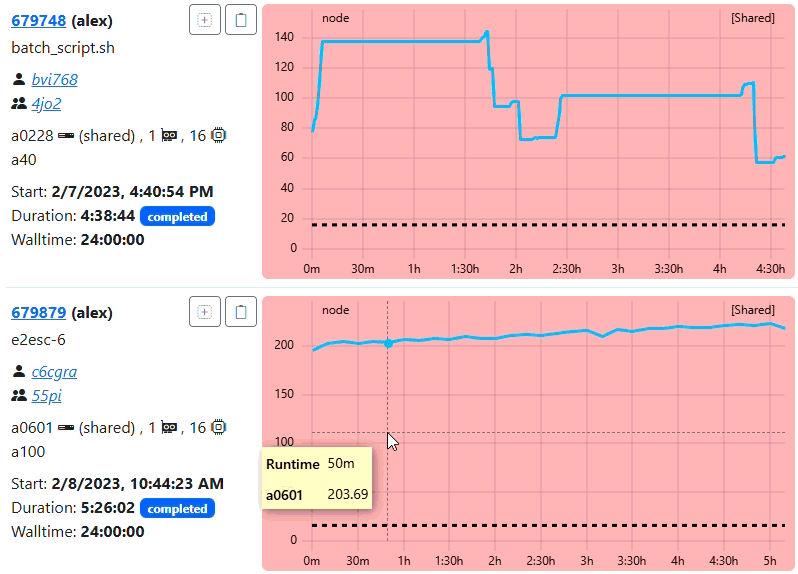
Suggestion on configuring the resampling
Based on the experiments we have done and the performance we have observed, we recommend the reader to:
- configure the
"minimum-points": 900. This means, assuming native frequency of 60, resampling will trigger for jobs > 15 hours of duration. - configure the
"resolutions"with 2 or 3 levels only, with the last level being native frequency. A resampling frequency of 600 is only recommended for jobs > 24 hours of duration.
14 - How to regenerate the Swagger UI documentation
Overview
This project integrates swagger ui to
document and test its REST API. The swagger documentation files can be found in
./api/.
Note
To regenerate the Swagger UI files is only required if you change the files./internal/api/rest.go. Otherwise the Swagger UI will already be correctly
build and is ready to use.Generate Swagger UI files
You can generate the swagger-ui configuration by running the following command from the cc-backend root directory:
go run github.com/swaggo/swag/cmd/swag init -d ./internal/api,./pkg/schema -g rest.go -o ./api
You need to move one generated file:
mv ./api/docs.go ./internal/api/docs.go
Finally rebuild cc-backend:
make
Use the Swagger UI web interface
If you start cc-backend with the -dev flag, the Swagger web interface is available
at http://localhost:8080/swagger/.
To use the Try Out functionality, e.g. to test the REST API, you must enter a JWT
key for a user with the API role.
Info
The user who owns the JWT key must not be logged into the same browser (have a valid session), or the Swagger requests will not work. It is recommended to create a separate user that has only the API role.15 - How to setup a systemd service
How to run as a systemd service.
The files in this directory assume that you install ClusterCockpit to
/opt/monitoring/cc-backend.
Of course you can choose any other location, but make sure you replace all paths
starting with /opt/monitoring/cc-backend in the clustercockpit.service file!
The config.json may contain the optional fields user and group. If
specified, the application will call
setuid and
setgid after reading the
config file and binding to a TCP port (so it can take a privileged port), but
before it starts accepting any connections. This is good for security, but also
means that the var/ directory must be readable and writeable by this user.
The .env and config.json files may contain secrets and should not be
readable by this user. If these files are changed, the server must be restarted.
- Clone this repository somewhere in your home
git clone git@github.com:ClusterCockpit/cc-backend.git
- (Optional) Install dependencies and build. In general it is recommended to use the provided release binaries.
cd cc-backend && make
Copy the binary to the target folder (adapt if necessary):
sudo mkdir -p /opt/monitoring/cc-backend/
cp ./cc-backend /opt/monitoring/cc-backend/
- Modify the
config.jsonandenv-template.txtfile from theconfigsdirectory to your liking and put it in the target directory
cp ./configs/config.json /opt/monitoring/config.json && cp ./configs/env-template.txt /opt/monitoring/.env
vim /opt/monitoring/config.json # do your thing...
vim /opt/monitoring/.env # do your thing...
- (Optional) Customization: Add your versions of the login view, legal texts, and logo image. You may use the templates in
./web/templatesas blueprint. Every overwrite is separate.
cp login.tmpl /opt/monitoring/cc-backend/var/
cp imprint.tmpl /opt/monitoring/cc-backend/var/
cp privacy.tmpl /opt/monitoring/cc-backend/var/
# Ensure your logo, and any images you use in your login template has a suitable size.
cp -R img /opt/monitoring/cc-backend/img
- Copy the systemd service unit file. You may adopt it to your needs.
sudo cp ./init/clustercockpit.service /etc/systemd/system/clustercockpit.service
- Enable and start the server
sudo systemctl enable clustercockpit.service # optional (if done, (re-)starts automatically)
sudo systemctl start clustercockpit.service
Check whats going on:
sudo systemctl status clustercockpit.service
sudo journalctl -u clustercockpit.service
16 - How to use the REST API Endpoints
Overview
ClusterCockpit offers several REST API Endpoints. While some are integral part of the ClusterCockpit-Stack Workflow (such asstart_job), others are optional.
These optional endpoints supplement the functionality of the webinterface with information reachable from scripts or the command line. For example, job metrics could be requested for specific jobs and handled in external statistics programs.
All of the endpoints listed for both administrators and users are secured by JWT authentication. As such, all prerequisites applicable to JSON Web Tokens apply in this case as well, e.g. private and public key setup.
See also the Swagger Reference for more detailed information on each endpoint and the payloads.
Admin Accessible REST API
Admin API Prerequisites
- JWT has to be generated by either a dedicated API user (has only
apirole) or by an administrator with bothadminandapiroles. - JWTs have a limited lifetime, i.e. will become invalid after a configurable amount of time (see
auth.jwt.max-ageconfig option). - Administrator endpoints are additionally subjected to a configurable IP whitelist (see
api-allowed-ipsconfig option). Per default there is no restriction on IPs that can access the endpoints.
Admin API Endpoints and Functions
| Endpoint | Method | Request Payload(s) | Description |
|---|---|---|---|
/api/users/ | GET | - | Lists all Users |
/api/clusters/ | GET | - | Lists all Clusters |
/api/tags/ | DELETE | JSON Payload | Removes payload array of tags specified with Type, Name, Scope from DB. Private Tags cannot be removed. |
/api/jobs/start_job/ | POST, PUT | JSON Payload | Starts Job |
/api/jobs/stop_job/ | POST, PUT | JSON Payload | Stops Jobs |
/api/jobs/ | GET | URL-Query Params | Lists Jobs |
/api/jobs/{id} | POST | $id, JSON Payload | Loads specified job metadata |
/api/jobs/{id} | GET | $id | Loads specified job with metrics |
/api/jobs/tag_job/{id} | POST, PATCH | $id, JSON Payload | Adds payload array of tags specified with Type, Name, Scope to Job with $id. Tags are created in BD. |
/api/jobs/tag_job/{id} | POST, PATCH | $id, JSON Payload | Removes payload array of tags specified with Type, Name, Scope from Job with $id. Tags remain in DB. |
/api/jobs/edit_meta/{id} | POST, PATCH | $id, JSON Payload | Edits meta_data db colums info |
/api/jobs/metrics/{id} | GET | $id, URL-Query Params | Loads specified jobmetrics for metric and scope params |
/api/jobs/delete_job/ | DELETE | JSON Payload | Deletes job specified in payload |
/api/jobs/delete_job/{id} | DELETE | $id, JSON Payload | Deletes job specified by db id |
/api/jobs/delete_job_before/{ts} | DELETE | $ts | Deletes all jobs before specified unix timestamp |
User Accessible REST API
User API Prerequisites
- JWT has to be generated by either a dedicated API user (Has only
apirole) or an User with additionalapirole. - JWTs have a limited lifetime, i.e. will become invalid after a configurable amount of time (see
jwt.max-ageconfig option).
User API Endpoints and Functions
| Endpoint | Method | Request | Description |
|---|---|---|---|
/userapi/jobs/ | GET | URL-Query Params | Lists Jobs |
/userapi/jobs/{id} | POST | $id, JSON Payload | Loads specified job metadata |
/userapi/jobs/{id} | GET | $id | Loads specified job with metrics |
/userapi/jobs/metrics/{id} | GET | $id, URL-Query Params | Loads specified jobmetrics for metric and scope params |
17 - How to use the Swagger UI documentation
Overview
This project integrates swagger ui to
document and test its REST API.
./api/.
Access the Swagger UI web interface
If you start cc-backend with the -dev flag, the Swagger web interface is available
at http://localhost:8080/swagger/.
To use the Try Out functionality, e.g. to test the REST API, you must enter a JWT
key for a user with the API role.